Googlebot خزنده وب گوگل است که برای جمعآوری اطلاعات موردنیاز و ایجاد یک نمایه قابل جستجو از وب استفاده میشود. Googlebot دارای خزندههای موبایل و دسکتاپ است و همچنین خزندههای ویژهای برای اخبار، تصاویر، ویدئوها و موارد دیگر دارد.
علاوه بر Googlebot، گوگل از خزندههای دیگری برای وظایف خاص استفاده میکند که هرکدام با یک رشته متنی متفاوت به نام "User-Agent"شناسایی میشوند. Googlebot همیشه بهروز است، به این معنی که وبسایتها را همانطور که کاربران در جدیدترین نسخه مرورگر Chromeمشاهده میکنند، پردازش میکند.
Googlebot Smartphone:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Googlebot Desktop:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36
گاهی اوقات:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Googlebot/2.1 (+http://www.google.com/bot.html)
Googlebotهای تخصصی:
Googlebot Image: Googlebot-Image/1.0
Googlebot Video: Googlebot-Video/1.0
Googlebot News: از User-Agent استاندارد Googlebot استفاده میکند.
StoreBot گوگل:
StoreBot Mobile:
Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36
Mozilla/5.0 (X11; Linux x86_64; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Safari/537.36
Google Inspection Tool:
Mobile:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0;)
Desktop:
Mozilla/5.0 (compatible; Google-InspectionTool/1.0;)
Google Other:
Mobile:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; GoogleOther)
Desktop:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GoogleOther) Chrome/W.X.Y.Z Safari/537.36
عبارت Chrome/W.X.Y.Zدر رشتههای User-Agent یک جایگزین است و نشاندهنده جدیدترین نسخه کرومی است که توسط Googlebot استفاده میشود.
Googlebot روی هزاران سرور اجرا میشود و تعیین میکند که با چه سرعتی و از کدام بخشهای وبسایتها خزیده شود. با این حال، برای جلوگیری از بار اضافی بر روی وبسایتها، سرعت خزیدن را کاهش میدهد.
طبق گزارش Cloudflare Radar، Googlebot سریعترین خزنده وب است و Ahrefsbotدر رتبه دوم قرار دارد.
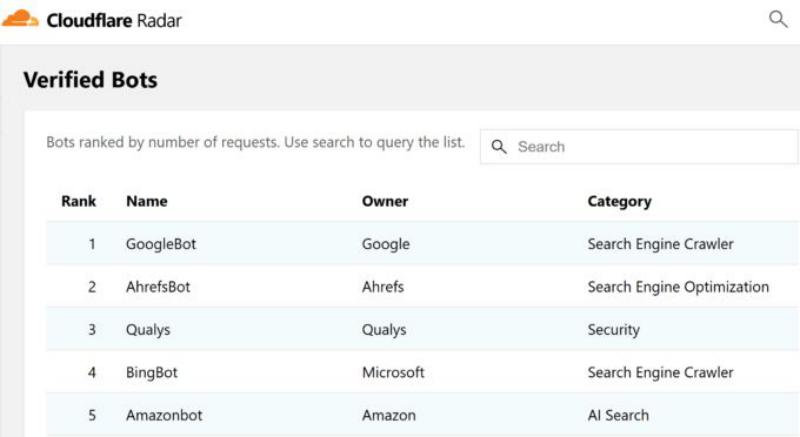

بیایید فرآیند آنها را برای ایجاد یک نمایه از وب بررسی کنیم.
نحوه خزیدن و ایندکس کردن وب توسط Googlebot
گوگل در گذشته چندین نسخه از فرآیند پردازش خود را به اشتراک گذاشته است. نسخه زیر، جدیدترین نسخه این فرآیند است.
Googlebot این فرآیند را دوباره اجرا کرده و به دنبال تغییرات صفحه یا لینکهای جدید میگردد. محتوای نسخه موبایلی صفحات رندر شده در نمایه گوگل ذخیره شده و قابل جستجو است. هر لینک جدیدی که پیدا شود، به فهرست URLهایی که باید خزیده شوند، اضافه میشود.
جزئیات بیشتری درباره این فرآیند را میتوانید در مقاله ما درباره نحوه کار موتورهای جستجو پیدا کنید. همچنین، اگر به جنبههای رندرینگ علاقهمند هستید، مقاله ما درباره سئوی جاوا اسکریپت را بررسی کنید.

گوگل این فرآیند را دوباره اجرا کرده و به دنبال تغییرات صفحه یا لینکهای جدید میگردد. محتوای نسخه موبایلی صفحات رندر شده همان چیزی است که در ایندکس گوگل ذخیره و قابل جستجو میشود. هر لینک جدیدی که پیدا شود، به فهرست URLهایی که باید خزیده شوند، اضافه میشود.
جزئیات بیشتری درباره این فرآیند را میتوانید در مقاله ما درباره نحوه کار موتورهای جستجو پیدا کنید. همچنین، اگر به رندرینگ صفحات علاقهمند هستید، مقاله ما درباره سئوی جاوا اسکریپت (JavaScript SEO)را بررسی کنید.
نحوه کنترل Googlebot
گوگل چندین روش برای کنترل خزیدن و ایندکس شدن محتوای وبسایت ارائه میدهد.
روشهای کنترل خزیدن
-
Robots.txt – این فایل در وبسایت شما مشخص میکند که کدام بخشها باید خزیده شوند.
- Nofollow – یک ویژگی لینک یا متا تگ robots که پیشنهاد میدهد یک لینک دنبال نشود. اما فقط یک راهنما است و ممکن است نادیده گرفته شود.
- تغییر نرخ خزیدن (منسوخ شده) – ابزاری در Google Search Console که امکان کاهش سرعت خزیدن گوگل را فراهم میکرد، اما اکنون منسوخ شده است.
روشهای کنترل ایندکس شدن
-
حذف محتوا اگر صفحهای را حذف کنید، دیگر قابل ایندکس نیست، اما برای کاربران نیز در دسترس نخواهد بود.
-
محدود کردن دسترسی به محتوا – گوگل به سایتها وارد نمیشود، بنابراین هرگونه احراز هویت یا محافظت با رمز عبور مانع از دسترسی آن به محتوا خواهد شد.
-
Noindex – استفاده از تگ متا noindexبه موتورهای جستجو اعلام میکند که صفحه نباید ایندکس شود.
-
ابزار حذف URL – این ابزار محتوای صفحه را بهطور موقت از نتایج جستجو پنهان میکند، اما گوگل همچنان آن را میبیند و میخزد.
-
Robots.txt (فقط برای تصاویر) مسدود کردن Googlebot Imageباعث میشود تصاویر سایت ایندکس نشوند.
مکان
Googlebot بیشتر از Mountain View، کالیفرنیا (در ساحل غربی ایالات متحده) خزیدن را انجام میدهد. البته، گوگل گزینههایی برای خزیدن از مناطق مختلف دارد، بهخصوص برای وبسایتهایی که دسترسی از ایالات متحده را مسدود کردهاند.
حداکثر اندازه فایل
-
برای بیشتر فایلها، گوگل اولین ۱۵ مگابایت (MB)از هر فایل را بررسی میکند.
-
برای فایلهای robots.txt، حداکثر اندازه ۵۰۰کیبیبایت (KiB)است.
پروتکل های انتقال پشتیبانی شده
Googlebot از HTTP/1.1و HTTP/2پشتیبانی میکند و بهطور خودکار پروتکلی را انتخاب میکند که عملکرد بهتری برای خزیدن سایت شما داشته باشد.
همچنین از FTP و FTPSنیز پشتیبانی میکند، اما این مورد کمتر رایج است.
فشردهسازی محتوا (Content Encoding)
Googlebot از فرمتهای gzip، deflate و Brotli (br)پشتیبانی میکند.
کشینگ HTTP
گوگل از استانداردهای کشینگ مانند ETagو Last-Modifiedپشتیبانی میکند و همچنین از هدرهای If-None-Matchو If-Modified-Sinceدر درخواستهای خود استفاده میکند.
آیا واقعاً Googlebot است؟
بسیاری از ابزارهای سئو و برخی رباتهای مخرب خود را بهعنوان Googlebotجا میزنند تا به وبسایتهایی که آنها را مسدود کردهاند، دسترسی پیدا کنند.
در گذشته، برای تأیید Googlebot باید یک DNS Lookupانجام میشد. اما اخیراً، گوگل این کار را آسانتر کرده و فهرستی از IPهای عمومی خود را منتشر کرده است که میتوانید از آن برای بررسی درخواستها در لاگ سرور خود استفاده کنید.
ابزار بررسی Googlebot
من ابزاری سریع ایجاد کردهام که فقط کافی است IPهای موجود در لاگ سرور خود را وارد کنید. این ابزار IPها را به یکی از دستههای زیر طبقهبندی میکند:
- Googlebot واقعی
- خزندههای ویژه گوگل (Special Crawlers)
- درخواستهای ایجاد شده توسط کاربر (User Triggered Fetches)
- درخواستهای ایجاد شده توسط کاربر (User Triggered Fetches - Google)
اگر IP نامعتبر باشد، نتیجه Unknownنمایش داده میشود.
فهرست IPها تا ۲۴ دسامبر ۲۰۲۴ بهروز شده است.
شما به گزارش "Crawl Stats"در Google Search Consoleنیز دسترسی دارید. با رفتن به مسیر Settings > Crawl Stats، میتوانید اطلاعات جامعی درباره نحوه خزیدن گوگل در وبسایت خود مشاهده کنید.
این گزارش نشان میدهد که کدام Googlebotدر حال خزیدن کدام فایلها است و در چه زمانی به آنها دسترسی داشته است.
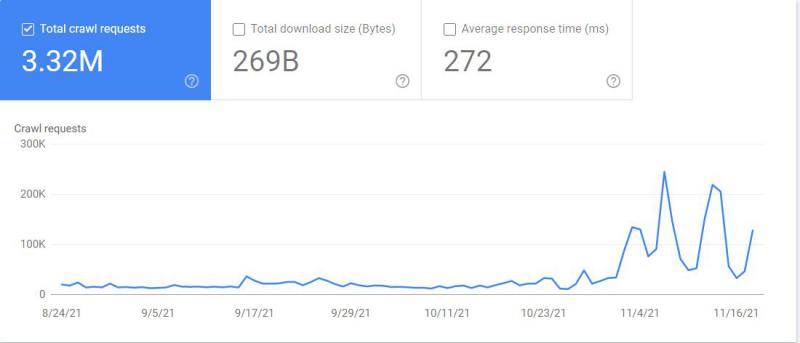
وب، دنیایی گسترده و پیچیده است. Googlebot باید در میان تنظیمات مختلف، محدودیتها و قطعیهای سایتها حرکت کند تا دادههای مورد نیاز موتور جستجوی گوگل را جمعآوری کند.
یک نکته جالب در این زمینه این است که Googlebot معمولاً بهعنوان یک ربات به تصویر کشیده میشود و به همین نام نیز شناخته شده است. همچنین، یک شعار عنکبوتی برای آن وجود دارد که "Crawley"نام دارد. طبق گفته Lizzi Harveyاز گوگل، این عنکبوت یک نام غیررسمی دیگر نیز دارد: "Dex" که کوتاهشده Indexاست.
Source :منبع