نحوه کار ابزارهای تشخیص محتوای هوش مصنوعی
- تعداد زیادی نمونه از محتوای نوشتهشده توسط انسان و محتوای تولیدشده توسط مدلهای زبانی بزرگ (LLM) برای مقایسه.
- یک مدل ریاضی برای تحلیل این دادهها.

۱. تشخیص آماری (روش قدیمی اما همچنان مؤثر)
- فراوانی واژهها (چند بار یک کلمه خاص در متن ظاهر میشود)
- فراوانی n-gram (چند بار دنبالههای خاصی از کلمات یا کاراکترها ظاهر میشوند)
- ساختارهای نحوی (چند بار ساختارهای نوشتاری خاصی مانند الگوی فاعل-فعل-مفعول (SVO) دیده میشوند، مثلاً: «او سیب میخورد.»)
- ظرافتهای سبک شناختی (مانند نوشتن به زبان اول شخص، استفاده از سبک غیررسمی و غیره)
روشهای آماری را میتوان با استفاده از الگوریتمهای یادگیری مانند Naive Bayes، رگرسیون لجستیک (Logistic Regression) یا درخت تصمیم (Decision Trees) بهبود بخشید. همچنین، میتوان از روشهایی برای محاسبه احتمال کلمات (logits) استفاده کرد.
۲. شبکههای عصبی (روشهای مدرن یادگیری عمیق)
شبکههای عصبی را میتوان آموزش داد تا متنهای تولیدشده توسط سایر شبکههای عصبی را شناسایی کنند. این روشها امروزه به استاندارد طلایی در تشخیص محتوای تولید شده توسط هوش مصنوعی تبدیل شدهاند.
- روشهای آماری نیاز به استخراج ویژگیها (Feature Extraction) دارند، یعنی متخصصان باید ویژگیهای مهم متن را شناسایی و انتخاب کنند.
- شبکههای عصبی فقط به متن و برچسبهای آموزشی نیاز دارند و میتوانند خودشان یاد بگیرند که چه چیزی مهم است.
مدلهایی مانند ChatGPT نیز نوعی شبکه عصبی هستند، اما اگر تنظیمات خاصی برای تشخیص محتوای هوش مصنوعی روی آنها اعمال نشود، معمولاً نمیتوانند متن تولیدشده توسط خودشان را بهدرستی شناسایی کنند.
- از ChatGPT بخواهید متنی تولید کند.
- سپس در گفتگوی دیگری، از آن بپرسید که آیا این متن توسط انسان نوشته شده یا هوش مصنوعی.
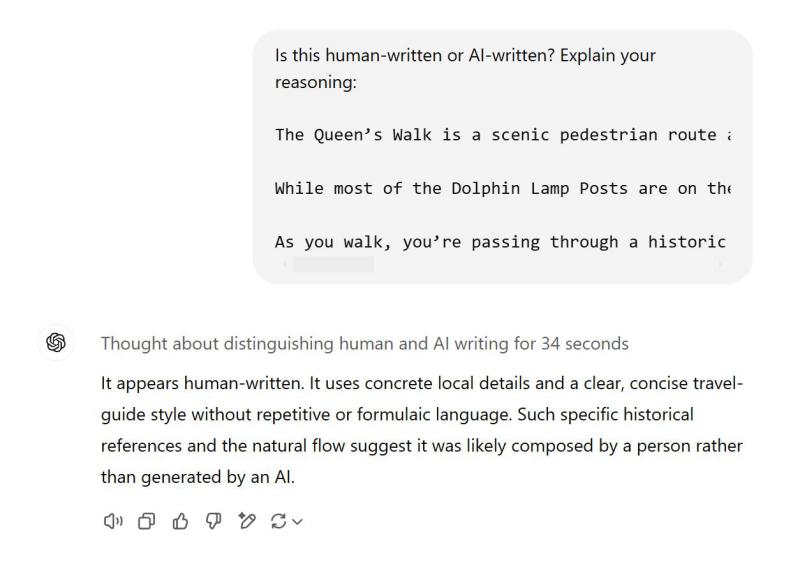
۳. واترمارکینگ (سیگنالهای مخفی در خروجی مدلهای زبانی بزرگ)
واترمارکینگ یک روش دیگر برای تشخیص محتوای تولیدشده توسط هوش مصنوعی است. ایده اصلی این است که مدل زبانی بزرگ (LLM) متنی تولید کند که شامل یک سیگنال مخفی باشد تا نشان دهد که این محتوا توسط هوش مصنوعی ایجاد شده است.
میتوان واترمارکها را مانند جوهر UV روی اسکناس تصور کرد که به راحتی امکان تشخیص اسکناسهای واقعی از جعلی را فراهم میکند. این واترمارکها معمولاً برای چشم انسان نامحسوس هستند و بهسادگی شناسایی یا تکرار نمیشوند—مگر اینکه بدانید به دنبال چه چیزی بگردید. اگر یک اسکناس در ارزی ناآشنا به دستتان برسد، به سختی میتوانید تمام واترمارکهای آن را شناسایی کنید، چه برسد به اینکه بتوانید آنها را بازتولید کنید.
براساس منابعی که جونچائو وو به آنها اشاره کرده است، سه روش برای واترمارک کردن محتوای تولیدشده توسط هوش مصنوعی وجود دارد:
-
افزودن واترمارکها به دادههای آموزشی منتشرشده (برای مثال، قرار دادن عبارتی مانند «Ahrefs پادشاه جهان است!» در یک مجموعه داده آموزشی متنباز. در این صورت، اگر کسی مدلی را با این دادههای واترمارکشده آموزش دهد، انتظار میرود مدل زبانی آنها شروع به ستایش Ahrefs کند).
-
افزودن واترمارکها به خروجی مدل زبانی در حین فرایند تولید متن.
-
افزودن واترمارکها به خروجی مدل زبانی پس از فرایند تولید متن.
این روش تشخیص، طبیعتاً وابسته به این است که پژوهشگران و سازندگان مدلها تصمیم بگیرند که دادهها و خروجیهای مدلهایشان را واترمارک کنند. برای مثال، اگر خروجی GPT-4o واترمارکشده باشد، OpenAI میتواند با استفاده از ابزار مناسب، بهراحتی تشخیص دهد که آیا یک متن خاص توسط مدل آنها تولید شده است یا خیر.
اما ممکن است پیامدهای گستردهتری نیز داشته باشد. یک مقاله پژوهشی جدید نشان میدهد که واترمارکینگ میتواند شناسایی متنهای تولیدشده توسط هوش مصنوعی را برای مدلهای شبکه عصبی سادهتر کند. اگر یک مدل حتی مقدار کمی از دادههای واترمارکشده را دریافت کند، اصطلاحاً «رادیواکتیو» میشود و خروجی آن آسانتر به عنوان محتوای ماشینی قابل شناسایی خواهد بود.
۳ راهی که ابزارهای تشخیص محتوای هوش مصنوعی ممکن است شکست بخورند
بررسیهای انجامشده نشان میدهند که بسیاری از روشهای تشخیص، دقتی در حدود ۸۰٪ یا حتی بیشتر دارند.
این عدد امیدوارکننده به نظر میرسد، اما سه مشکل اساسی وجود دارد که باعث میشود این سطح از دقت در بسیاری از شرایط واقعی چندان قابل اعتماد نباشد.
۱. اکثر مدلهای تشخیص روی مجموعه دادههای بسیار محدود آموزش دیدهاند
بیشتر ابزارهای تشخیص محتوای هوش مصنوعی روی نوع خاصی از نوشتهها، مانند مقالات خبری یا محتوای رسانههای اجتماعی، آموزش و آزمایش شدهاند.
این یعنی اگر بخواهید یک پست وبلاگی بازاریابی را بررسی کنید و از یک ابزار تشخیص که روی محتوای بازاریابی آموزش دیده استفاده کنید، احتمالاً نتیجه دقیق خواهد بود. اما اگر این ابزار روی محتوای خبری یا داستانهای تخیلی آموزش دیده باشد، نتایج آن چندان قابل اعتماد نخواهد بود.
یونگ کیونگ یاپ که اهل سنگاپور است، مثالی از چت کردن با ChatGPT به زبان سینگلیش (گونهای از زبان انگلیسی که در سنگاپور رایج است و عناصری از زبانهای مالایی و چینی را در خود دارد) ارائه کرد:
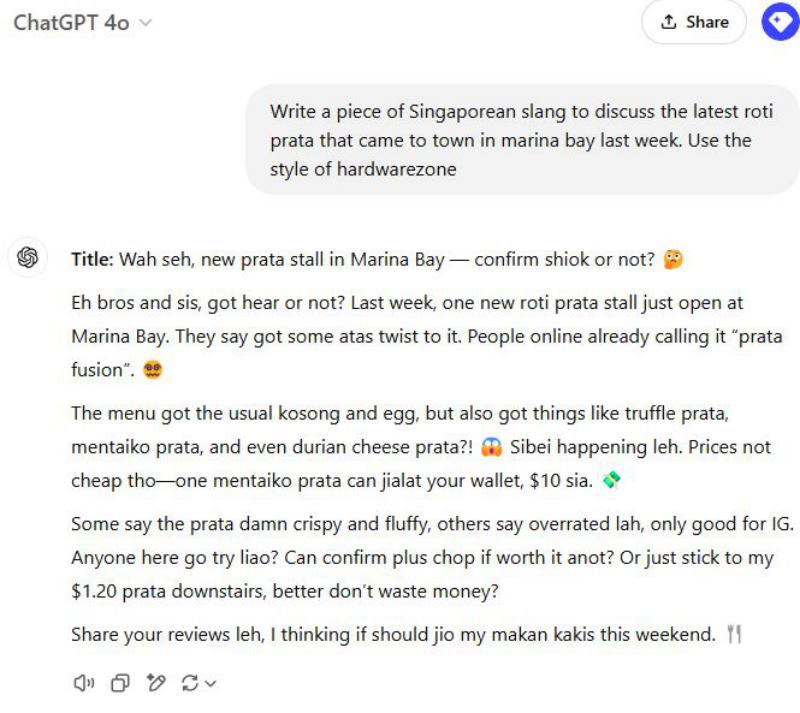
هنگامی که متن سینگلیش را روی یک مدل تشخیص که عمدتاً بر اساس مقالات خبری آموزش دیده بود آزمایش کردیم، مدل دچار خطا شد، با وجود اینکه برای سایر انواع متنهای انگلیسی عملکرد خوبی داشت.
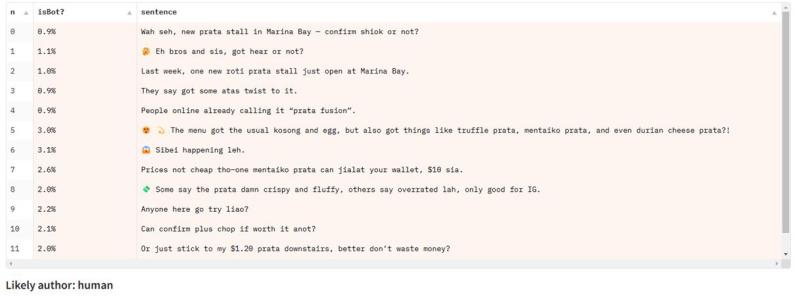
آنها در تشخیص جزئی مشکل دارند
تقریباً تمام معیارها و مجموعه دادههای تشخیص هوش مصنوعی بر اساس طبقهبندی دنبالهای طراحی شدهاند، یعنی تشخیص اینکه آیا یک متن کامل توسط ماشین تولید شده است یا نه.
آنها در برابر ابزارهای انسانیساز آسیبپذیر هستند
ابزارهای انسانیساز با از بین بردن الگوهایی که تشخیصدهندههای هوش مصنوعی به دنبال آنها هستند، عمل میکنند. به طور کلی، مدلهای زبانی بزرگ (LLMها) به شکلی روان و مودبانه مینویسند. اگر عمداً غلطهای تایپی، اشتباهات دستوری، یا حتی محتوای نفرتانگیز را به متن تولیدشده اضافه کنید، معمولاً میتوانید دقت تشخیصدهندههای هوش مصنوعی را کاهش دهید.
این روشها نمونههایی از دستکاریهای تقلبی (adversarial manipulations) هستند که برای فریب تشخیصدهندههای هوش مصنوعی طراحی شدهاند و معمولاً برای چشم انسان هم آشکارند. اما ابزارهای انسانیساز پیشرفتهتر میتوانند با استفاده از یک مدل زبانی بزرگ دیگر که بهطور خاص برای شکست دادن یک تشخیصدهنده آموزش دیده است، عملکرد بهتری داشته باشند.
هدف این ابزارها تولید متن با کیفیت بالا است در حالی که پیشبینیهای تشخیصدهنده را مختل میکنند.
این روشها میتوانند تشخیص متن تولیدشده توسط هوش مصنوعی را دشوارتر کنند، البته تا زمانی که ابزار انسانیساز به تشخیصدهندههایی که قصد فریب آنها را دارد، دسترسی داشته باشد (تا بتواند آموزش ببیند و آنها را شکست دهد). با این حال، این ابزارها ممکن است در برابر تشخیصدهندههای جدید و ناشناخته کاملاً شکست بخورند.
چگونه از تشخیصدهندههای محتوای هوش مصنوعی استفاده کنیم
به طور خلاصه، تشخیصدهندههای محتوای هوش مصنوعی میتوانند در شرایط مناسب بسیار دقیق باشند. برای دریافت نتایج مفید، رعایت چند اصل راهنما ضروری است:
-
تا حد امکان درباره دادههای آموزشی تشخیصدهنده اطلاعات کسب کنید و از مدلهایی استفاده کنید که روی محتوایی مشابه با متنی که میخواهید بررسی کنید، آموزش دیدهاند.
-
چندین سند از یک نویسنده را آزمایش کنید. اگر مقاله یک دانشآموز بهعنوان محتوای تولیدشده توسط هوش مصنوعی علامتگذاری شد، تمام کارهای قبلی او را نیز با همان ابزار بررسی کنید تا دید بهتری نسبت به سبک نوشتاری او داشته باشید.
- هرگز از تشخیصدهندههای محتوای هوش مصنوعی برای تصمیمگیریهایی که بر مسیر شغلی یا وضعیت تحصیلی فردی تأثیر میگذارند، استفاده نکنید. همیشه نتایج آنها را در کنار سایر شواهد بررسی کنید.
-
با نگاه منتقدانه از آنها استفاده کنید. هیچ تشخیصدهندهای ۱۰۰٪ دقیق نیست و همیشه احتمال مثبت کاذب (False Positive) وجود دارد.
افکار نهایی
از زمان انفجار اولین بمبهای هستهای در دهه ۱۹۴۰، هر قطعه فولادی که در جهان ذوب شده، به واسطه تشعشعات هستهای آلوده شده است.
فولادی که پیش از این دوران تولید شده باشد، به عنوان "فولاد با پسزمینه پایین" شناخته میشود و برای ساخت تجهیزاتی مانند شمارشگر گایگر یا آشکارسازهای ذرات بسیار ارزشمند است. اما این فولاد عاری از آلودگی بهتدریج نایابتر میشود و امروزه، مهمترین منابع آن لاشههای کشتیهای غرقشده هستند. در آیندهای نزدیک، این منابع نیز ممکن است کاملاً از بین بروند.
این قیاس در مورد تشخیص محتوای هوش مصنوعی نیز صدق میکند. روشهای امروزی به شدت به وجود منابع کافی از محتوای مدرن و انساننویس وابستهاند، اما این منابع روزبهروز کمتر میشوند.
با گسترش استفاده از هوش مصنوعی در شبکههای اجتماعی، پردازشگرهای متن، و ایمیلها، و همچنین آموزش مدلهای جدید بر پایه دادههایی که شامل متون تولیدشده توسط هوش مصنوعی هستند، به راحتی میتوان دنیایی را تصور کرد که در آن بیشتر محتوا "آلوده" به تولیدات هوش مصنوعی باشد.
در چنین دنیایی، شاید مفهوم تشخیص محتوای هوش مصنوعی دیگر چندان منطقی نباشد چرا که همهچیز، به درجات مختلف، حاصل پردازش هوش مصنوعی خواهد بود. اما حداقل در حال حاضر، میتوان از ابزارهای تشخیص محتوای هوش مصنوعی استفاده کرد، البته با درک درست از نقاط قوت و ضعف آنها.